rocBLAS design and usage notes#
This topic covers the structure, organization, and concepts underlying rocBLAS. It also includes some notes on how to use rocBLAS effectively.
Use of Tensile and hipBLASLt#
The rocBLAS library uses Tensile and hipBLASLt internally, which supply high-performance implementations of GEMM. Tensile is installed as part of the rocBLAS package, while hipBLASLt is available as a separate package. By default, the rocBLAS library is built with Tensile and depends on the external hipBLASLt library.
rocBLAS uses CMake for building, which by default downloads the Tensile component during library configuration and automatically builds it as an integrated part of the rocBLAS build. No further set-up work is required by the user. For hermetic builds, the Tensile component can be built from a local path installation (see command line options). Note that external facing APIs for Tensile are not provided.
The choice of whether to use the embedded Tensile backend or hipBLASLt is handled automatically based on the architecture and problem. For instance, hipBLASLt is used as the default backend for problems on the gfx12 architecture. Source code GEMMs internal to the rocBLAS library also allow rocBLAS to be built without Tensile or hipBLASLt. They can potentially be used as fallbacks for problems that are not supported by the Tensile or hipBLASLt backends.
The environment variables ROCBLAS_USE_HIPBLASLT and ROCBLAS_USE_HIPBLASLT_BATCHED are provided to manually control which GEMM backend is used. ROCBLAS_USE_HIPBLASLT is for non-batched, _strided_batched and _batched GEMM. ROCBLAS_USE_HIPBLASLT_BATCHED only affects _batched GEMM. These provide the following settings:
ROCBLAS_USE_HIPBLASLTandROCBLAS_USE_HIPBLASLT_BATCHEDare not set: the GEMM backend is automatically selected.ROCBLAS_USE_HIPBLASLT=0: Tensile is always used as the GEMM backend.ROCBLAS_USE_HIPBLASLT_BATCHED=0: Tensile is always used as the GEMM _batched backend.ROCBLAS_USE_HIPBLASLT=1: hipBLASLt is preferred as the GEMM backend, but the backend will fall back to Tensile for problems for which hipBLASLt does not provide a solution or if errors are encountered using the hipBLASLt backend.
Note
The hipBLASLt backend for rocBLAS is currently not supported on static builds, and is not included if building without Tensile.
rocBLAS API and legacy BLAS functions#
rocBLAS is initialized by calling rocblas_create_handle and is terminated by calling rocblas_destroy_handle.
The rocblas_handle is persistent and contains:
The HIP stream
The temporary device workspace
The mode for enabling or disabling logging (the default is logging disabled)
rocBLAS functions run on the host. They call HIP to launch rocBLAS kernels that run on the device in a HIP stream. The kernels are asynchronous unless:
The function returns a scalar result from device to host
Temporary device memory is allocated
In both cases above, the launch can be made asynchronous by:
Using
rocblas_pointer_mode_deviceto keep the scalar result on the device. Only the following Level-1 BLAS functions return a scalar result:Xdot,Xdotu,Xdotc,Xnrm2,Xasum,iXamax, andiXamin.Using the device memory functions provided to allocate persistent device memory in the handle. Note that most rocBLAS functions do not allocate temporary device memory.
Before calling a rocBLAS function, arrays must be copied to the device. Integer scalars like m, n, and k are stored on the host. Floating point scalars like alpha and beta can be on the host or device.
Error handling is performed by returning a rocblas_status. Functions conform to the legacy BLAS argument checking.
Rules for obtaining the rocBLAS API from legacy BLAS functions#
The legacy BLAS routine name is changed to lowercase and prefixed by
rocblas_<function>. For example, the legacy BLAS routineSSCAL, which scales a vector by a constant value, is replaced withrocblas_sscal.An initial argument of
rocblas_handlehandle is added to all rocBLAS functions.Input arguments are declared with the
constmodifier.Character arguments are replaced with enumerated types defined in
rocblas_types.h. They are passed by value on the host.Array arguments are passed by reference on the device.
Scalar arguments are passed by value on the host with the following exceptions. See the Pointer mode section for more information:
Scalar values alpha and beta are passed by reference on either the host or the device.
When legacy BLAS functions have return values, the return value is instead added as the last function argument. It is returned by reference on either the host or the device. This applies to the following functions:
xDOT,xDOTU,xDOTC,xNRM2,xASUM,IxAMAX, andIxAMIN.
The return value of all functions is
rocblas_status, which is defined inrocblas_types.h. It is used to check for errors.
rocBLAS example code#
Below is a simple example for calling the function rocblas_sscal:
#include <iostream>
#include <vector>
#include "hip/hip_runtime_api.h"
#include "rocblas.h"
using namespace std;
int main()
{
rocblas_int n = 10240;
float alpha = 10.0;
vector<float> hx(n);
vector<float> hz(n);
float* dx;
rocblas_handle handle;
rocblas_create_handle(&handle);
// allocate memory on device
hipMalloc(&dx, n * sizeof(float));
// Initial Data on CPU,
srand(1);
for( int i = 0; i < n; ++i )
{
hx[i] = rand() % 10 + 1; //generate a integer number between [1, 10]
}
// copy array from host memory to device memory
hipMemcpy(dx, hx.data(), sizeof(float) * n, hipMemcpyHostToDevice);
// call rocBLAS function
rocblas_status status = rocblas_sscal(handle, n, &alpha, dx, 1);
// check status for errors
if(status == rocblas_status_success)
{
cout << "status == rocblas_status_success" << endl;
}
else
{
cout << "rocblas failure: status = " << status << endl;
}
// copy output from device memory to host memory
hipMemcpy(hx.data(), dx, sizeof(float) * n, hipMemcpyDeviceToHost);
hipFree(dx);
rocblas_destroy_handle(handle);
return 0;
}
LP64 interface#
The rocBLAS library default implementations are LP64, so rocblas_int arguments are 32 bit and
rocblas_stride arguments are 64 bit.
ILP64 interface#
The rocBLAS library functions are also available with ILP64 interfaces. With these interfaces,
all rocblas_int arguments are replaced by the type name
int64_t. These ILP64 function names all end with the suffix _64. The only output arguments that change are for
xMAX and xMIN, where the index is now int64_t. Performance should match the LP64 API when problem sizes don’t require additional
precision. Function-level documentation is not repeated for these APIs because they are identical in behavior to the LP64 versions.
However, functions which support this alternate API include the line:
This function supports the 64-bit integer interface (ILP64).
When parameters exceeding the internal maximum supported size are provided
the functions will return rocblas_status_invalid_size. This is most often for symmetric matrix dimensions larger than the int32_t max value,
for which such large memory allocation is not practical.
Column-major storage and 1-based indexing#
rocBLAS uses column-major storage for 2D arrays, and 1-based indexing
for the functions xMAX and xMIN. This is the same as legacy BLAS and
cuBLAS.
If you require row-major and 0-based indexing (used in C language arrays), download the file cblas.tgz from the Netlib Repository.
Review the CBLAS functions that provide a thin interface to legacy BLAS. They convert from row-major and 0-based to column-major and
1-based. This is done by swapping the order of the function arguments. It is not necessary to transpose the matrices.
Pointer mode#
The auxiliary functions rocblas_set_pointer and rocblas_get_pointer are
used to set and get the value of the state variable
rocblas_pointer_mode. This variable is stored in rocblas_handle. If rocblas_pointer_mode ==
rocblas_pointer_mode_host, then scalar parameters must be allocated on
the host. If rocblas_pointer_mode == rocblas_pointer_mode_device, then
scalar parameters must be allocated on the device.
There are two types of scalar parameters:
Scaling parameters like alpha and beta used in functions like
axpy,gemv, andgemmScalar results from the functions
amax,amin,asum,dot, andnrm2
Scalar parameters like alpha and beta can be allocated on the host heap or
stack when rocblas_pointer_mode == rocblas_pointer_mode_host.
The kernel launch is asynchronous, so if the parameters are on the heap,
they can be freed after the return from the kernel launch. When
rocblas_pointer_mode == rocblas_pointer_mode_device, the parameters must not be
changed until the kernel completes.
For scalar results when rocblas_pointer_mode ==
rocblas_pointer_mode_host, the function blocks the CPU until the GPU
has copied the result back to the host. When rocblas_pointer_mode ==
rocblas_pointer_mode_device, the function returns after the
asynchronous launch. Like the vector and matrix results, the scalar
result is only available when the kernel has completed execution.
Asynchronous API#
rocBLAS functions are asynchronous unless:
The function needs to allocate device memory
The function returns a scalar result from GPU to CPU
The order of operations in the asynchronous functions is shown in the figure below. The argument checking, calculation of the process grid, and kernel launch take very little time. The asynchronous kernel running on the GPU does not block the CPU. After the kernel launch, the CPU continues processing the instructions.
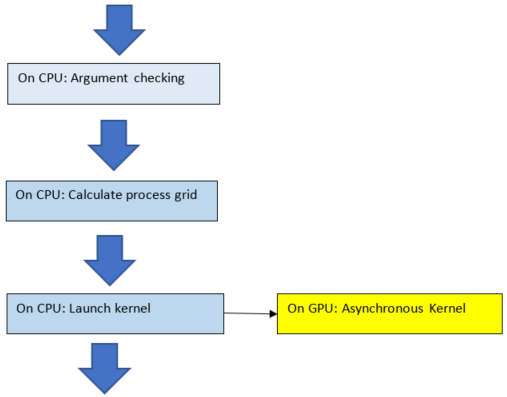
Order of operations in asynchronous functions#
The order of operations above will change if logging is enabled or the function is synchronous. Logging requires system calls, so the program must wait for them to complete before executing the next instruction. For more information, see Logging in rocBLAS.
Note
The default setting has logging disabled.
If the CPU needs to allocate device memory, it must wait until memory allocation is complete before executing the next instruction. For more detailed information, refer to the sections Device memory allocation in rocBLAS and Device memory allocation.
Note
Memory can be pre-allocated. This makes the function asynchronous because it removes the need for the function to allocate memory.
The following functions copy a scalar result from GPU to CPU if
rocblas_pointer_mode == rocblas_pointer_mode_host:
asumdotmaxminnrm2
This makes the function synchronous because the program must wait for the copy before executing the next instruction. See Pointer mode for more information.
Note
You can make a function asynchronous by setting rocblas_pointer_mode == rocblas_pointer_mode_device.
This keeps the result on the GPU.
The order of operations for logging, device memory allocation, and return of a scalar result is shown in the figure below:
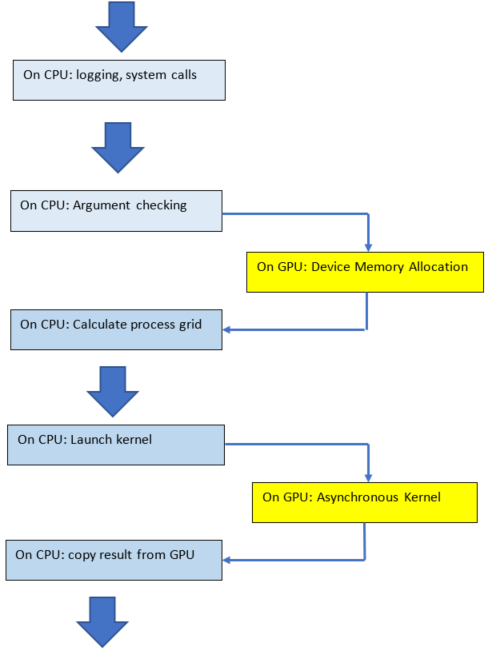
Code blocks in a synchronous function call#
Kernel launch status error checking#
The function hipExtGetLastError() is called after a rocBLAS kernel launches.
This function detects if the launch parameters are incorrect, for example,
an invalid work group or thread block size. It also determines if the kernel code is unable to
run on the current GPU device. In that case, it returns a status of rocblas_status_arch_mismatch.
Thus most rocblas API functions that launch kernels will flush a pre-existing error.
You can check for any previous HIP error before calling a rocBLAS API function
by calling hipGetLastError().
Complex number data types#
The data types for rocBLAS complex numbers in the API are a special case.
For C compiler users, gcc, and other non-amdclang compiler users, these types
are exposed as a struct with x and y components and an identical memory layout
to std::complex for float and double precision. Internally, a templated
C++ class is defined, but it should be considered deprecated for external use.
For simplified usage with Hipified code, there is an option
to interpret the API as using the hipFloatComplex and hipDoubleComplex types
(for instance, typedef hipFloatComplex rocblas_float_complex). This is made available
for users to avoid casting when using the HIP complex types in their code.
The memory layout is consistent across all three types, so
it is safe to cast arguments to API calls between the three types: hipFloatComplex,
std::complex<float>, and rocblas_float_complex, as well as for
the double-precision variants. To expose the API using the HIP-defined
complex types, use either a compiler define or an inlined
#define ROCM_MATHLIBS_API_USE_HIP_COMPLEX before including the header file <rocblas.h>.
The API is therefore compatible with both forms, but
recompilation is required to avoid casting if you are switching to pass in the HIP complex types.
Most device memory pointers are passed with void*
types to the HIP utility functions (for example, hipMemcpy), so uploading memory from std::complex arrays
or hipFloatComplex arrays doesn’t require changes
regardless of the complex data type API choice.
Atomic operations#
Some functions within the rocBLAS library such as gemv, symv, trsv, trsm,
and gemm can use atomic operations to increase performance.
By using atomics, functions might not give bit-wise reproducible results.
Differences between multiple runs should not be significant and the results will
remain accurate. If you want to allow atomic operations, see rocblas_atomics_mode,
rocblas_set_atomics_mode(), and rocblas_get_atomics_mode().
In addition to the API above, rocBLAS also provides the environment variable ROCBLAS_DEFAULT_ATOMICS_MODE,
which lets users set the default atomics mode during the creation of rocblas_handle.
rocblas_set_atomics_mode() has higher precedence, so users can use
the API in an application to override the environment variable configuration setting.
The following settings apply to ROCBLAS_DEFAULT_ATOMICS_MODE:
ROCBLAS_DEFAULT_ATOMICS_MODE = 0: Sets the default torocblas_atomics_not_allowedROCBLAS_DEFAULT_ATOMICS_MODE = 1: Sets the atomics torocblas_atomics_allowed
Bitwise reproducibility#
In rocBLAS, bitwise-reproducible results can be obtained under the following conditions:
Identical GFX target ISA
Single HIP stream active per rocBLAS handle
Identical ROCm versions
Atomic operations are not allowed (for more information, see Atomic operations)
By default, atomic operations are not allowed. All other functions are bitwise reproducible by default.
Note
Functions such as GEMV and TRSM use temporary device memory to allow optimized kernels to achieve higher performance.
If device memory is unavailable, these functions proceed to use an unoptimized kernel, which could also produce variable results.
To notify users that an unoptimized kernel is being used, the function returns the rocblas_status_perf_degraded status.
Functions that can be enabled to use atomic operations#
Note
This list also includes all Level-3 functions.
Instinct MI100 (gfx908) considerations#
On nodes using the MI100 (gfx908) GPU, Matrix-Fused-Multiply-Add (MFMA)
instructions are available to substantially speed up matrix operations.
This hardware feature is used in all GEMM and GEMM-based functions in
rocBLAS with 32-bit or shorter base data types with an associated 32-bit
compute_type (f32_r, i32_r, or f32_c as applicable).
Specifically, rocBLAS takes advantage of MI100’s MFMA instructions for
three real base types f16_r, bf16_r, and f32_r with compute_type f32_r,
one integral base type i8_r with compute_type i32_r, and one complex
base type f32_c with compute_type f32_c. In summary, all GEMM APIs and
APIs for GEMM-based functions using these five base types and their
associated compute_type (explicit or implicit) take advantage of MI100’s
MFMA instructions.
Note
The MI100’s MFMA instructions are used automatically. There is no user setting to turn this functionality on or off.
Not all problem sizes consistently select the MFMA-based kernels. Additional tuning might be required to achieve good performance.
Instinct MI200 (gfx90a) Considerations#
On nodes using the MI200 (gfx90a) GPU, MFMA_F64 instructions are available to
substantially speed up double-precision matrix operations. This
hardware feature is used in all GEMM and GEMM-based functions in
rocBLAS with 64-bit floating-point data types: DGEMM, ZGEMM,
DTRSM, ZTRSM, DTRMM, ZTRMM, DSYRKX, and ZSYRKX.
The MI200 MFMA_F16, MFMA_BF16, and MFMA_BF16_1K instructions
flush subnormal input/output data (“denorms”) to zero.
In some instances, use cases utilizing the HPA (High Precision Accumulate) HGEMM
kernels where a_type=b_type=c_type=d_type=f16_r and compute_type=f32_r
do not work well with the MI200’s flush-denorms-to-zero behavior.
The is due to the limited exponent range of the F16 data types.
rocBLAS provides an alternate implementation of the
HPA HGEMM kernel that uses the MFMA_BF16_1K instruction. It
takes advantage of the much larger exponent range of BF16, although with reduced
accuracy. To select the alternate implementation of HPA HGEMM with the
gemm_ex or gemm_strided_batched_ex functions, use
the enum value of rocblas_gemm_flags_fp16_alt_impl for the flags argument.
Note
The MI200’s MFMA instructions (including MFMA_F64) are used automatically. There is no user setting to turn this functionality on or off.
Not all problem sizes consistently select the MFMA-based kernels. Additional tuning might be required to achieve good performance.